GPT-ARIA: GPT-3 as a User-Agent


I’ve been thinking about browser automation since the early days of my career when I worked at Firefox, where I got to work on big problems around performance and built things like Firefox Telemetry (Hi, HN haters!). With the rise of large language models (LLMs)—and OpenAI’s recent launch of ChatGPT plugins—people are getting excited about browser agents again. My favorite demo so far is natbot, Nat Friedman’s GPT-3-powered browser agent that he launched last October.
Natbot got me thinking about other ways that LLMs could be used to improve web browsing, as well as some of the drawbacks of an HTML-only approach. If we used AI to double down on the “Agent” in User-Agent (Browser), we could do things like:
Support visually impaired users. One of my most intelligent family members is visually impaired and doesn’t speak English. Browsers could do a better job helping her translate and read web pages.
Increase age-appropriate content. Could we simplify content and graphics for children?
Support different input modalities. This includes gesture and voice interfaces for users who might struggle with a keyboard and mouse.
Provide context-specific browsing UI. Web browsing is challenging (or dangerous) when performing chores, driving, etc. Content and interaction modes should be adjusted to the context and limitations of the user.
Support user-controlled content curation. We could all benefit from undoing SEO-ization of the web, e.g. having an LLM-based re-ranker, summarizer of content, etc.
After investigating the natbot code, I was in awe of the simplicity of the underlying source code. Combining a Python scraper, an HTML-to-text converter, and an LLM that issues shortcuts, it could perform browser actions like “Find a 2-bedroom house for sale in Anchorage, AK for under $250K” or “Make a reservation for 4 for dinner at Dorsia in New York City at 8pm.”
Its shortcomings weren’t intrinsic to natbot, but to its data source: raw HTML. Within modern web pages, HTML is rarely able to perfectly map to what is rendered for the user. Feeding only HTML to GPT-3 leaves it with no idea of how the page actually renders, and so natbot relies heavily on the cleverness of its Python translation layer and on selecting demos where the DOM tree coincides tightly with the rendered page.
Enter ARIA
The same year I joined Mozilla, the W3C launched ARIA, a set of standards for appending HTML with semantics and other metadata to make web pages more accessible. Chrome (and Firefox!) dev tools expose an accessibility tree (ARIA tree) of page content, which powers things like screen readers for visually-impaired internet users.
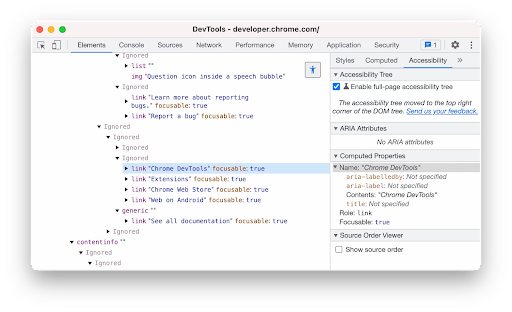
Unlike the DOM, which is close to the original HTML, the ARIA tree is a text version of the rendered result of that DOM, processed by the browser’s rendering pipeline. If implemented well (not a given), it is a more faithful representation of the rendered web page than the source.
It seems that if we could build a bridge between structures designed for screen readers and GPT-3, we could get GPT-3 to more “natively” ingest web pages. The model could then make decisions based on a fairly complete representation of the rendered webpage. This seemed so obvious that I was surprised no one had done it before.
Not-So-Simple Implementation
The idea seemed simple—build a natbot-inspired browser agent using the ARIA tree, not the DOM, as the data source. But implementation turned out to be pretty challenging.
The first obstacle was gaining access to the ARIA tree from inside of a Chrome extension. Turns out it’s impossible, so we leaned on Puppeteer, which still has various frustrating limitations (the biggest one is not having a good way to map ARIA back to DOM nodes). The second challenge came up in trying to share a state machine between an LLM and a Puppeteer-controlled browser. It's no easy feat. At first, we developed code to serialize the browser state into GPT and turn GPT completions into browser interactions. Eventually, we settled on formatting the prompt as a typescript file, which serves both as a description of datatypes for the typescript program and a prompt prefix for the model (so cool that the same text can be a JS library and LLM prompt!). This avoided a lot of duplication between prompt and supporting code that I’ve seen in other GPT interactions. Check this out for a diagram of the interaction between GPT and the browser.
The third challenge was prompt engineering. Writing code and writing prompts are very different kinds of work, and I found it hard to context-switch between them. Luckily, Ben was able to show a lot of empathy for GPT-3 and point out where I was confusing it. He was also most adept at proposing prompting strategies and figured out how to teach GPT-3 to draw conclusions based on observations gathered from multiple pages.
With a limited context window, we had to trim the ARIA tree to fit and could only provide a few examples instructing GPT-3 on how to interpret the tree. Despite that, GPT-3’s comprehension seemed surprisingly good (though I am still not completely convinced of that). Adding scrolling support and/or migrating to GPT-4 with its larger context window would be nice, but that’s a project for another day.
In conclusion
I was originally hoping that ARIA-GPT could improve screen readers by using GPT-3 to summarize web content. This project didn’t close the door on that idea, but it did remind me just how hard (and rewarding) it is to work with browsers. None of it is easy—from extracting content, to automating browser actions, to expressing all of that as a pleasant user experience.
The lack of end-to-end prompt-testing tools was also very frustrating. Tiny changes in our prompt changed LLM behavior, and we struggled to assess the overall impact of a prompt change on browser control. Also, given the latency of GPT-3, a snappy browsing experience might be better achieved by a smaller, faster and perhaps web-browser-specific local model.
In the end, building this prototype raised more questions than it answered. I think there is a lot to be done in modernizing browsers with LLMs. We hit the limitations of GPT-3.5 (we’ll have to test GPT-4 now), but I’m undoubtedly excited about the future of smart agents trawling the web on a user’s behalf.
Demos
While ARIA-GPT is still very much a work in progress, we were pleasantly surprised by some of the early results:
What’s the price of an iPhone?
get-aria: determining price of iPhone
Who was the king of England when Lviv(my hometown) was founded?
https://www.youtube.com/watch?v=VJIddKmQdPc
In the readme, we include further examples where the model performs searches using Bing and DuckDuckGo. I find its flexibility remarkable given the limited examples provided in prompt.ts.
This was the most interesting prototype I’ve explored in my career so far, and I want to thank Oleksandr Chugai for helping with implementation and Ben Cmejla who helped with prompting.
P.S. I first encountered this idea of smart agents in the 1995 book, The Road Ahead by Bill Gates. As recently as 2020, he was complaining that agents were still too far out. Bill, we got you buddy!
Up Next
Partnering with Kenzo Security
Helping defenders move faster than threats

The Art of Intelligence
AI knows everything we've done, but perhaps nothing we've felt
